Awesome FAQ: a Markdown FAQ Site
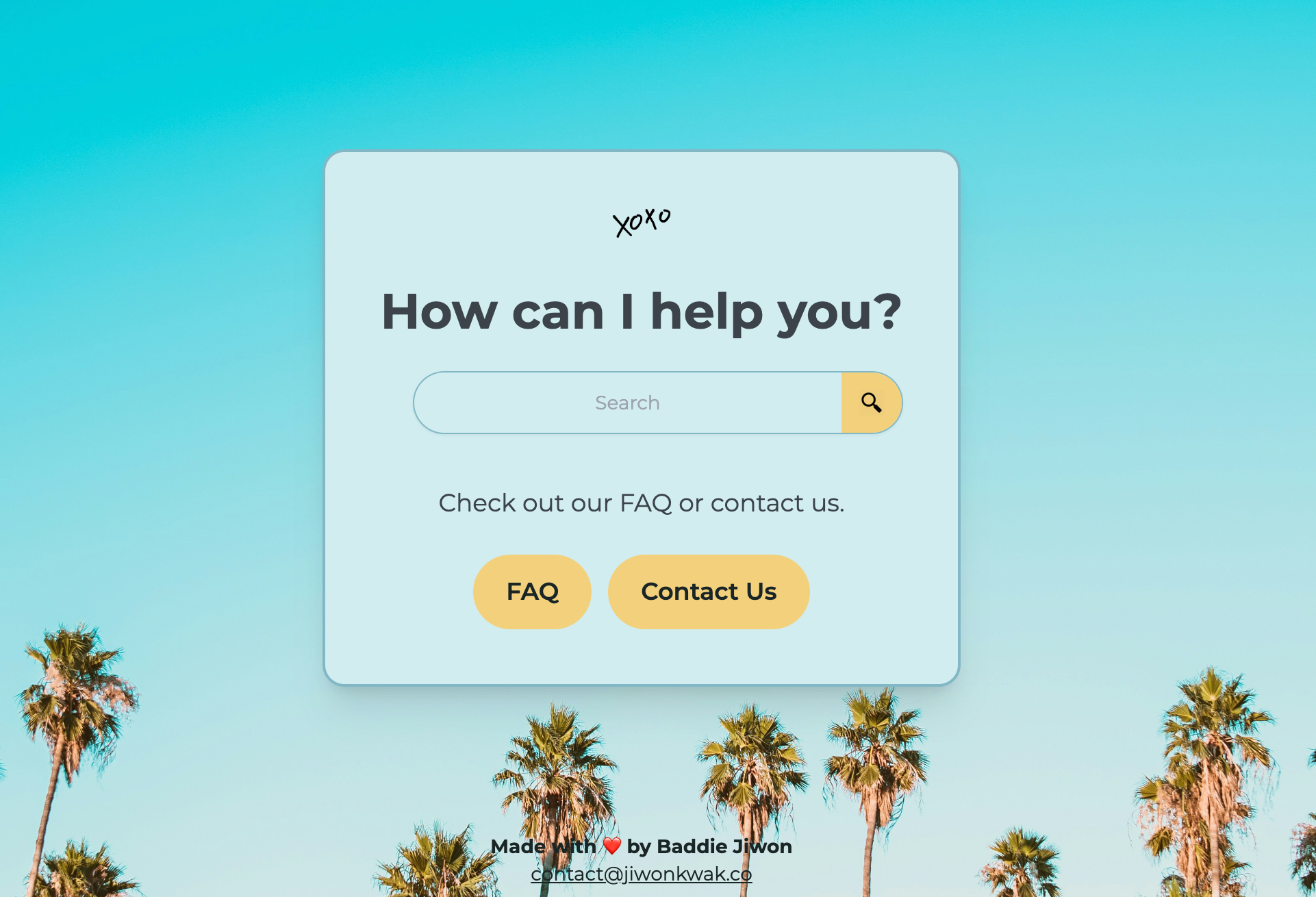
Every engineering team faces the same problem: scattered technical knowledge. In my case, I noticed our team kept getting the same technical questions, which led to redundant discussions and wasted time.
Instead of relying on manual document updates (which no one wants to maintain), I built an automated FAQ system—one that:
- Uses Markdown for simplicity.
- Auto-updates categories & search via a Node.js script.
- Removes outdated FAQs & empty categories dynamically.
- Generates a structured FAQ summary without human intervention.
What started as a humble prototype over a weekend evolved into a structured, searchable system after several iterations, feedback loops, and a few CSS-induced existential crises. It’s now polished enough to open-source.
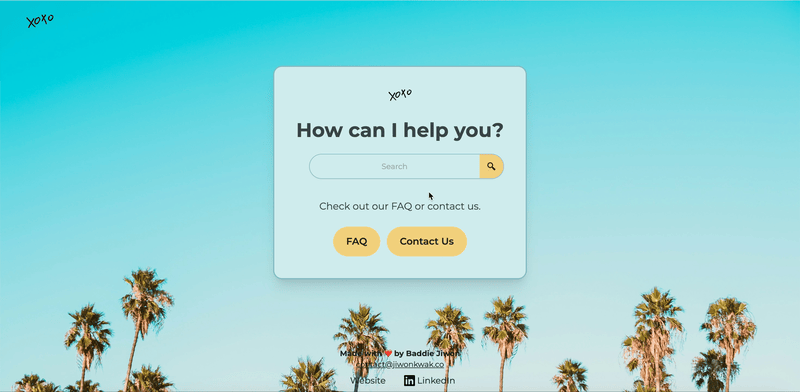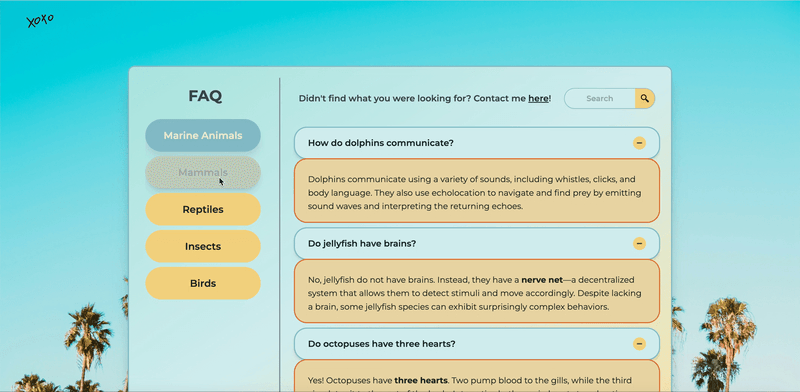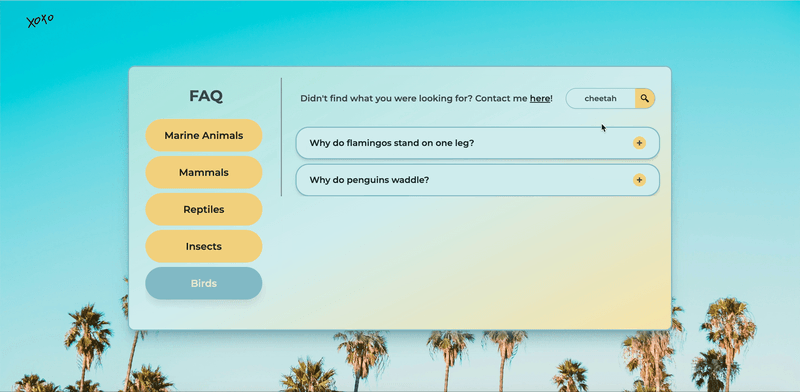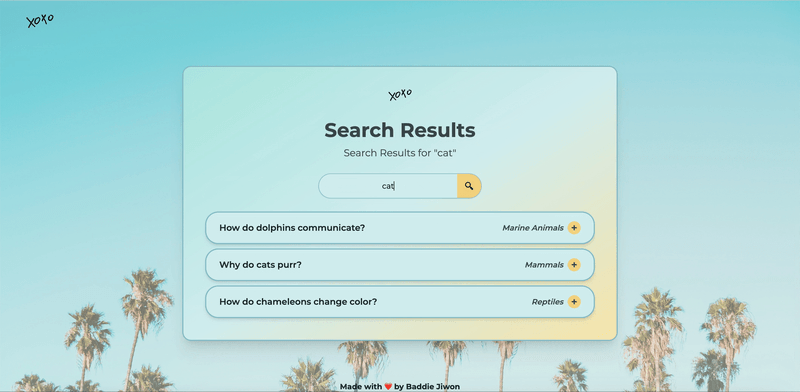
How it works
Markdown-Based
I evaluated different approaches for storing FAQs:
- Database-backed system: Overkill for a simple FAQ.
- Static JSON-based system: Hard to edit manually.
- Markdown files: Lightweight, easy to version-control, and developer-friendly.
Ultimately, I chose Markdown + Eleventy because it allows FAQs to be stored as flat files, which makes it easy for engineers to contribute via Git.
This also meant I needed a script to dynamically process FAQs—which led to the next challenge: categorization and automated updates.
(And this project allowed me some room for creativity: the world was my CSS oyster.)
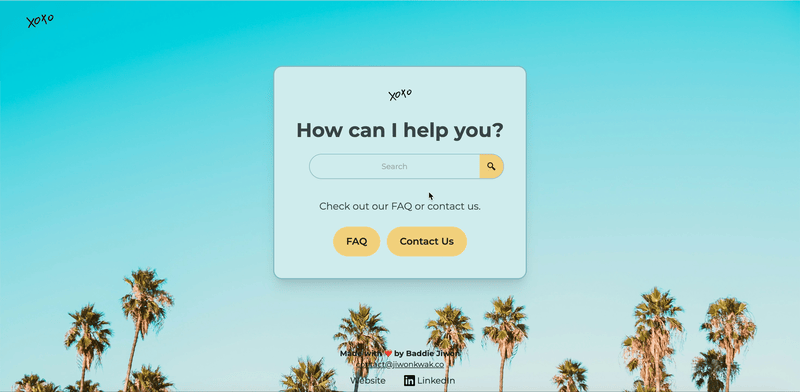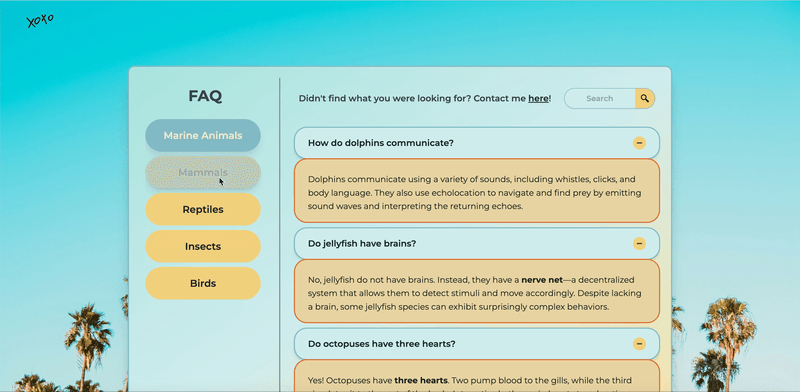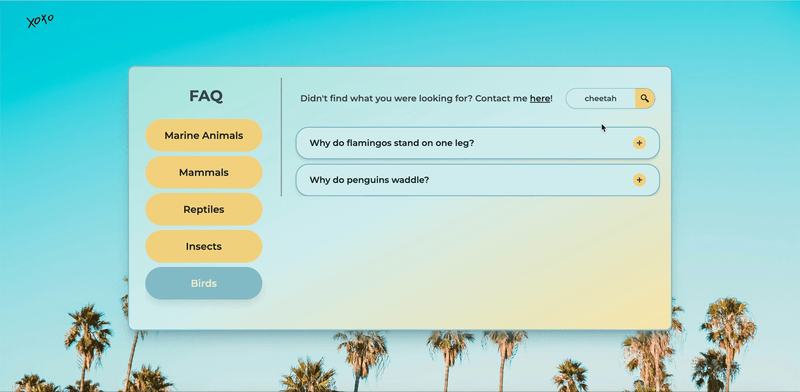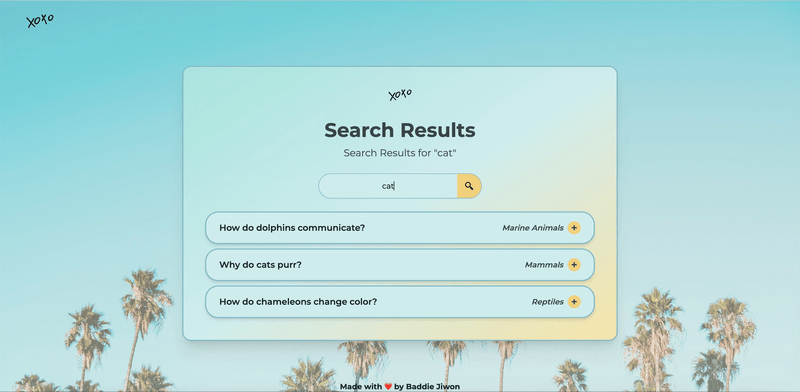
Auto-Categorized UI
No manual updates. No missing FAQs. I built a system where each .md file contains a category field in front matter, and a Node.js script auto-updates the UI.
- New FAQs automatically appear under the right category.
- Deleted files disappear from the UI—no manual cleanup needed.
Efficiency at its finest.
Easily Customizable UI with Tailwind.css
I wanted a design system that was both flexible and fast to iterate on. Tailwind turned out to be the perfect choice—especially when styling elements individually, like buttons.
The syntax takes a little getting used to, but once you get the hang of it, it’s surprisingly intuitive.
Auto-Generated FAQ Summary
Since each FAQ is stored as its own .md file, keeping an overview of all topics isn't easy. Sure, we could manually maintain a list—but let’s be honest, humans forget things.
So, I automated it. The script auto-generates faq-summary.txt, adding, updating, or removing entries as needed. No extra work, no forgotten updates.
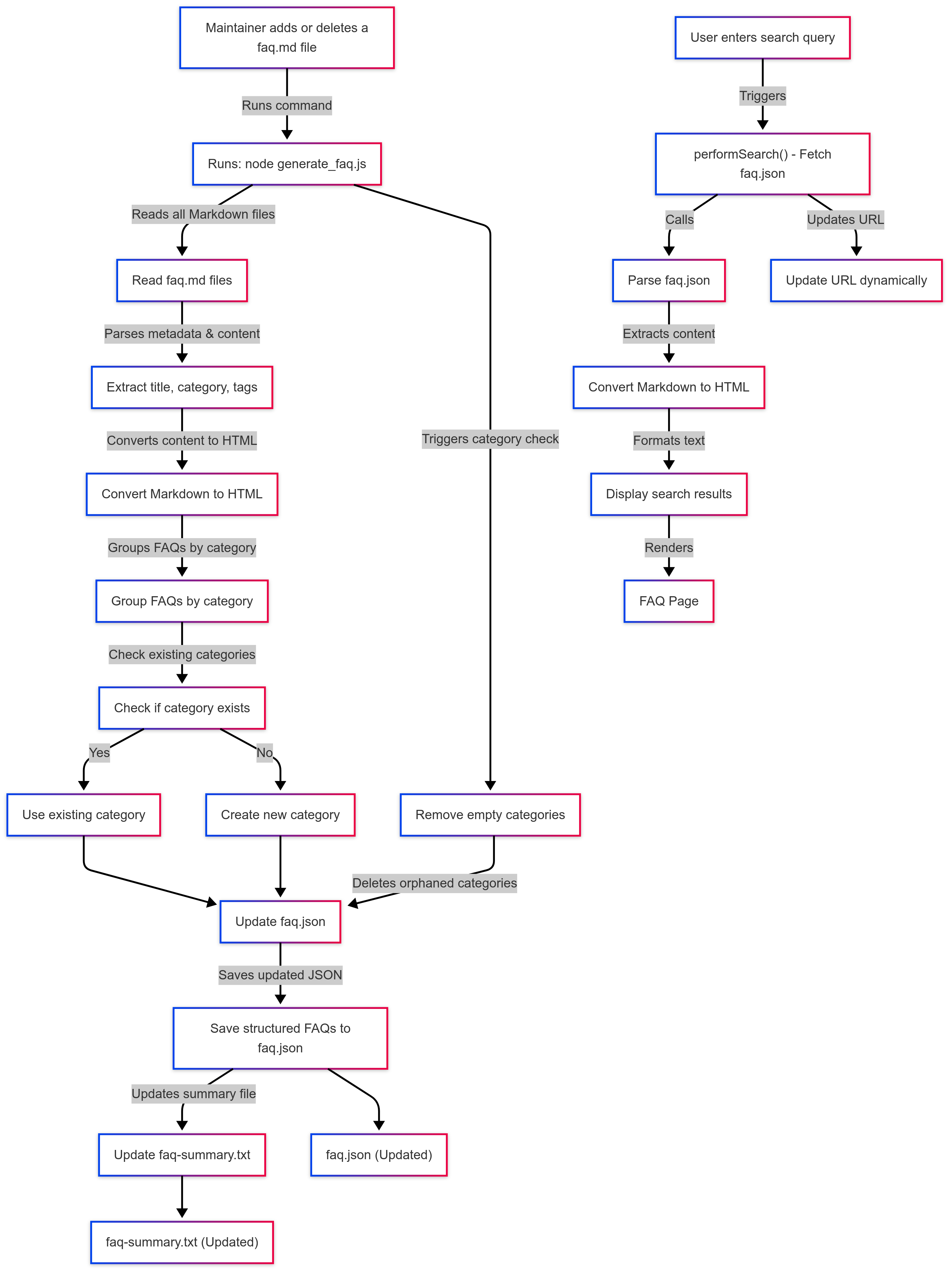
FAQ Processing Script: Step-by-Step Breakdown
This script auto-categorizes, removes outdated FAQs, and generates summaries, so everything stays clean and searchable.
Here’s how it works.
Prerequisites
- Dependencies:
fs,path,gray-matter,marked. - Files:
faq.json– Stores all FAQ datafaq/– Directory containing.mdfilesfaq-summary.txt– Auto-generated summary of FAQs
Step 1: Load and Parse FAQ Categories
Why validate faq.json first?
- A corrupted
faq.jsonfile can break the entire system. - It’s better to fail fast than risk storing broken data.
let faqCategories;
try {
faqCategories = JSON.parse(fs.readFileSync(faqJsonPath, "utf8"));
if (!Array.isArray(faqCategories)) {
console.warn("⚠️ Warning: `faq.json` format is incorrect.");
process.exit(1);
}
} catch (error) {
console.error("❌ Error parsing `faq.json`:", error);
process.exit(1);
}
// Debug: Log loaded FAQ categories
console.log("✅ Loaded FAQ Categories:", faqCategories.length, "categories");
// Get today's date
const today = new Date().toISOString().split("T")[0];
// Track if updates are made
let updated = false;
- Explanation: Parses
faq.jsonintofaqCategories. If it’s not an array or fails to parse, the script exits with an error. Logs the count for sanity—because counting categories is oddly satisfying.
Step 2: Scan and Process Markdown FAQ Files
- Key Problem: How do we keep the UI updated automatically when
.mdfiles change? - Solution: Each
.mdfile includes a front matter field (category), and the script dynamically updates categories & removes old FAQs.
Now, we scour the faq/ directory for .md files, extract their metadata, and update or add them to the right category. It’s like herding cats, but with files.
// **STEP 1: Scan for existing Markdown FAQ files**
const faqFiles = fs.readdirSync(faqDirectory).filter(file => file.endsWith(".md"));
const existingTitles = new Set(); // Track existing titles to detect deleted ones
faqFiles.forEach(file => {
const filePath = path.join(faqDirectory, file);
const fileContent = fs.readFileSync(filePath, "utf8");
const parsed = matter(fileContent); // Extract front matter metadata
const title = parsed.data.title || file.replace(".md", ""); // Default to filename if no title
const category = parsed.data.category || "Uncategorized"; // Default category
const tags = parsed.data.tags || []; // Tags from front matter
const body = parsed.content.trim(); // Extract markdown body
const cleanedBody = body.replace(/^#+ /gm, "");
const htmlBody = marked.parseInline(cleanedBody);
existingTitles.add(title); // Store title as existing
// **STEP 1.1: Remove FAQ from any previous category**
faqCategories.forEach(cat => {
cat.faqs = cat.faqs.filter(faq => faq.title !== title);
});
// **STEP 1.2: Find or create the new category**
let categoryEntry = faqCategories.find(c => c.category === category);
if (!categoryEntry) {
categoryEntry = { category: category, faqs: [] };
faqCategories.push(categoryEntry);
}
// **STEP 1.3: Add or update the FAQ in the correct category**
let existingFAQ = categoryEntry.faqs.find(faq => faq.title === title);
if (existingFAQ) {
// **Update existing FAQ**
existingFAQ.tags = tags;
existingFAQ.body = htmlBody;
existingFAQ.author = defaultAuthor;
existingFAQ.createdDate = today;
existingFAQ.fileName = file;
} else {
// **Add new FAQ if it doesn't exist**
categoryEntry.faqs.push({
title: title,
slug: title.toLowerCase().replace(/\s+/g, "-"),
tags: tags,
body: htmlBody,
author: defaultAuthor,
createdDate: today,
fileName: file
});
}
updated = true;
});
- Explanation:
- Scans
.mdfiles, extracts front matter (title, category, tags) withgray-matter.
- Scans
- Auto-generates missing categories.
- Ensures UI stays up-to-date without manual intervention.
Step 3: Remove Stale Data
Problem: What if an .md file gets deleted but still appears in the FAQ UI?
Solution: The script removes orphaned FAQs & prunes empty categories automatically.
We clean up—any FAQ without a matching .md file gets the boot. Efficiency over sentimentality.
// **STEP 2: Remove FAQs that no longer have corresponding Markdown files**
faqCategories.forEach(category => {
category.faqs = category.faqs.filter(faq => existingTitles.has(faq.title));
});
// **STEP 3: Remove empty categories before saving `faq.json`**
faqCategories = faqCategories.filter(category => category.faqs.length > 0);
- Explanation:
- Filters out FAQs whose titles aren’t in
existingTitles, ensuringfaq.jsonreflects only current files. - No stale FAQs cluttering the UI.
- Ensures every category has at least one FAQ.
- Filters out FAQs whose titles aren’t in
Step 4: Generate FAQ Summary File
Finally, we generate faq-summary.txt, a neatly structured Markdown table—because spreadsheets are overrated. The script scans Markdown FAQ files, extracts metadata (file name, category, title, etc.), and automatically updates the summary. It even sorts FAQs numerically to keep the newest entries at the bottom. Just edit your .md files, and the summary updates like magic!
let markdownContent = `# FAQ Summary
## Maintained by: Jiwon
## Last Updated: ${today}
| File Name | Category | Title | Author | Created Date |
|----------------|-------------|-----------------------------------------|---------|--------------|
`;
// Flatten all FAQs into a single array for sorting
let allFaqs = [];
faqCategories.forEach(category => {
category.faqs.forEach(faq => {
allFaqs.push({
fileName: faq.fileName,
category: category.category,
title: faq.title,
author: faq.author,
createdDate: faq.createdDate
});
});
});
// **Sort by file number, extracting numeric parts and sorting in ascending order**
allFaqs.sort((a, b) => {
let numA = parseInt(a.fileName.match(/\d+/)?.[0] || "0", 10);
let numB = parseInt(b.fileName.match(/\d+/)?.[0] || "0", 10);
return numA - numB; // Sorting in ascending order (most recent at the bottom)
});
// Append sorted FAQs to markdown content
allFaqs.forEach(faq => {
markdownContent += `| ${faq.fileName} | ${faq.category} | ${faq.title} | ${faq.author} | ${faq.createdDate} |\n`;
});
// **STEP 5: Write to faq-summary.txt**
try {
fs.writeFileSync(faqTxtPath, markdownContent, "utf8");
console.log("Awesomesss! FAQ is up to date!");
} catch (error) {
console.error("❌ Error writing `faq-summary.txt`:", error);
}
- Explanation:
- Builds a Markdown table of all FAQs.
Saves it to faq-summary.txt.
This project taught me valuable lessons about automation, data processing, and scalability.
- Error handling is crucial—even a small JSON corruption can break the entire workflow.
- Keeping things simple works—Markdown + Eleventy was the best decision for this use case.
- Automation beats manual updates—the script ensures the FAQ is always accurate.
Check out the GitHub repo: [https://github.com/jiwon-lieb/faq_md].